

AI brokers are reshaping software program growth, from writing code to finishing up complicated directions. But LLM-based brokers are susceptible to errors and infrequently carry out poorly on sophisticated, multi-step duties. Reinforcement studying (RL) is an method the place AI programs be taught to make optimum choices by receiving rewards or penalties for his or her actions, bettering by means of trial and error. RL may also help brokers enhance, nevertheless it usually requires builders to extensively rewrite their code. This discourages adoption, although the info these brokers generate might considerably enhance efficiency by means of RL coaching.
To handle this, a analysis workforce from Microsoft Analysis Asia – Shanghai has launched Agent Lightning. This open-source (opens in new tab) framework makes AI brokers trainable by means of RL by separating how brokers execute duties from mannequin coaching, permitting builders so as to add RL capabilities with just about no code modification.
Capturing agent habits for coaching
Agent Lightning converts an agent’s expertise right into a format that RL can use by treating the agent’s execution as a sequence of states and actions, the place every state captures the agent’s standing and every LLM name is an motion that strikes the agent to a brand new state.
This method works for any workflow, regardless of how complicated. Whether or not it entails a number of collaborating brokers or dynamic instrument use, Agent Lightning breaks it down right into a sequence of transitions. Every transition captures the LLM’s enter, output, and reward (Determine 1). This standardized format means the info can be utilized for coaching with none extra steps.

Hierarchical reinforcement studying
Conventional RL coaching for brokers that make a number of LLM requests entails stitching collectively all content material into one lengthy sequence after which figuring out which components ought to be realized and which ignored throughout coaching. This method is troublesome to implement and might create excessively lengthy sequences that degrade mannequin efficiency.
As a substitute, Agent Lightning’s LightningRL algorithm takes a hierarchical method. After a process completes, a credit score task module determines how a lot every LLM request contributed to the result and assigns it a corresponding reward. These impartial steps, now paired with their very own reward scores, can be utilized with any present single-step RL algorithm, corresponding to Proximal Coverage Optimization (PPO) or Group Relative Coverage Optimization (GRPO) (Determine 2).
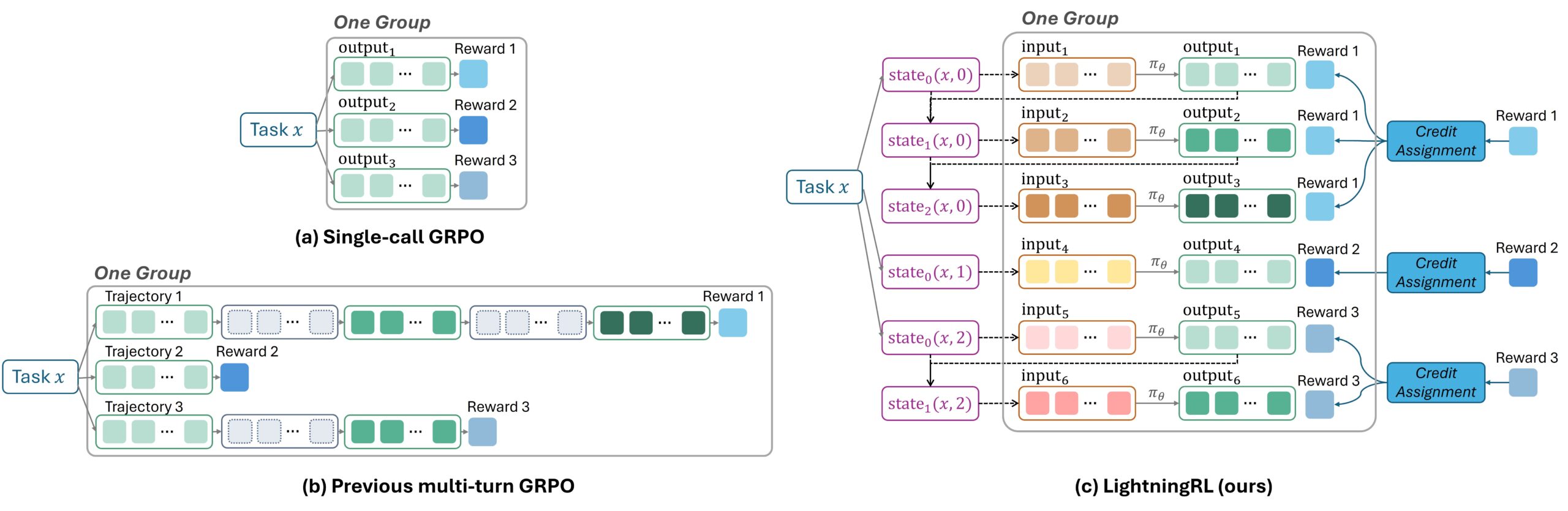
This design affords a number of advantages. It stays absolutely appropriate with extensively used single-step RL algorithms, permitting present coaching strategies to be utilized with out modification. Organizing information as a sequence of impartial transitions lets builders flexibly assemble the LLM enter as wanted, supporting complicated behaviors like brokers that use a number of instruments or work with different brokers. Moreover, by preserving sequences quick, the method scales cleanly and retains coaching environment friendly.
Agent Lightning as middleware
Agent Lightning serves as middleware between RL algorithms and agent environments, offering modular parts that allow scalable RL by means of standardized protocols and well-defined interfaces.
An agent runner manages the brokers as they full duties. It distributes work and collects and shops the outcomes and progress information. It operates individually from the LLMs, enabling them to run on completely different assets and scale to help a number of brokers working concurrently.
An algorithm trains the fashions and hosts the LLMs used for inference and coaching. It orchestrates the general RL cycle, managing which duties are assigned, how brokers full them, and the way fashions are up to date based mostly on what the brokers be taught. It usually runs on GPU assets and communicates with the agent runner by means of shared protocols.
The LightningStore (opens in new tab) serves because the central repository for all information exchanges throughout the system. It supplies standardized interfaces and a shared format, guaranteeing that the completely different parts can work collectively and enabling the algorithm and agent runner to speak successfully.

All RL cycles observe two steps: (1) Agent Lightning collects agent execution information (referred to as “spans”) and retailer them within the information retailer; (2) it then retrieves the required information and sends it to the algorithm for coaching. Via this design, the algorithm can delegate duties asynchronously to the agent runner, which completes them and studies the outcomes again (Determine 4).

One key benefit of this method is its algorithmic flexibility. The system makes it straightforward for builders to customise how brokers be taught, whether or not they’re defining completely different rewards, capturing intermediate information, or experimenting with completely different coaching approaches.
One other benefit is useful resource effectivity. Agentic RL programs are complicated, integrating agentic programs, LLM inference engines, and coaching frameworks. By separating these parts, Agent Lightning makes this complexity manageable and permits every half to be optimized independently
A decoupled design permits every element to make use of the {hardware} that fits it greatest. The agent runner can use CPUs whereas mannequin coaching makes use of GPUs. Every element may also scale independently, bettering effectivity and making the system simpler to take care of. In apply, builders can hold their present agent frameworks and swap mannequin calls to the Agent Lightning API with out altering their agent code (Determine 5).

Analysis throughout three real-world situations
Agent Lightning was examined on three distinct duties, reaching constant efficiency enhancements throughout all situations (Determine 6):
Textual content-to-SQL (LangChain): In a system with three brokers dealing with SQL technology, checking, and rewriting, Agent Lightning concurrently optimized two of them, considerably bettering the accuracy of producing executable SQL from pure language queries.
Retrieval-augmented technology (OpenAI Brokers SDK implementation): On the multi-hop question-answering dataset MuSiQue, which requires querying a big Wikipedia database, Agent Lightning helped the agent generate simpler search queries and purpose higher from retrieved content material.
Mathematical QA and power use (AutoGen implementation): For complicated math issues, Agent Lightning skilled LLMs to extra precisely decide when and methods to name the instrument and combine the outcomes into its reasoning, rising accuracy.

Enabling steady agent enchancment
By simplifying RL integration, Agent Lightning could make it simpler for builders to construct, iterate, and deploy high-performance brokers. We plan to increase Agent Lightning’s capabilities to incorporate computerized immediate optimization and extra RL algorithms.
The framework is designed to function an open platform the place any AI agent can enhance by means of real-world apply. By bridging present agentic programs with reinforcement studying, Agent Lightning goals to assist create AI programs that be taught from expertise and enhance over time.
Leave a Reply